Hemos estado hablando en anteriores posts de distintas técnicas de agrupación y clasificación, pero este tipo de algoritmos de aprendizaje automático permiten realizar muchas otras tareas, como por ejemplo implementar un motor de recomendación.
En este post vamos a explicar en qué consisten estos sistemas de recomendación, y veremos algunos ejemplos básicos de como utilizarlos, sus ventajas e inconvenientes, y una aproximación a su implementación en Python.
Aquí va este pequeño tutorial para crear fácilmente un motor de recomendación de productos en Python.
De qué estamos hablando
Actualmente estoy precisamente trabajando en mi empresa (Solusoft.es) en una plataforma de recomendación avanzada, que emplea diversos mecanismos y técnicas para proporcionar los mejores resultados en cada caso, y después de todo el tiempo dedicado a ello lo primero que diría es que cuando pensamos en un motor de recomendación no estamos hablando únicamente de los típicos productos destacados de un modo u otro que aparecen por ejemplo en la web de Amazon, o en Spotify o Netflix. Un motor de recomendación podría recomendar cualquier tipo de elemento a cualquier tipo de destinatario, ajustando los resultados en función de parámetros de toda índole. Para ello a menudo hay mecanismos genéricos más o menos flexibles, pero en otras ocasiones ha sido recomendable emplear tecnologías (ElasticSearch, Neo4j…) o técnicas específicas que funcionan para resolver un problema concreto, o incluso en muchas ocasiones desarrollar nuestros propios algoritmos.
El objetivo de este post, sin embargo, es esbozar los fundamentos de un motor de recomendación, facilitando su comprensión, por lo que en este caso no veremos ejemplos peculiares, sino que nos limitaremos precisamente a los típicos que mencionaba en el párrafo anterior, ya que además de clásicos son los más utilizados y por lo tanto también los más aplicables y fáciles de entender.
Con este propósito me centraré en particular en el Filtrado Colaborativo.
Filtrado Colaborativo (User-based Collaborative Filtering)
El filtrado colaborativo es una técnica esencial de aprendizaje automático aplicado a motores de recomendación. Consiste basicamente en la construcción de una matriz de usuarios * productos, donde cada columna corresponde a un producto de nuestro catálogo (sea lo que sea), cada fila corresponde a un usuario, y cada celda recoge un valor numérico que corresponde al interés (o similar) de ese usuario por ese producto en particular.
Esta matriz se va completando a medida que los usuarios interactúan con los productos, de forma que cuando un usuario puntúa una serie en netflix por ejemplo, iremos a la celda correspondiente y estableceremos la valoración de ese usuario para esa serie. De este modo la matriz se va poblando de datos.
Después, la técnica consiste en detectar similaridad entre los usuarios, esto es, buscar usuarios que han asignado puntuaciones similares a las que tú has asignado a los mismos productos.
Una vez que se han localizado los usuarios similares, llegamos al tercer y último paso: seleccionamos aquellos productos que estos “usuarios similares”; disfrutaron más, y que nuestro usuario objetivo aún no ha visto, y estas serán precisamente las recomendaciones.
Si quisieramos, podriamos aplicar la tecnica de forma equivalente basandonos en el numero de veces que los usuarios vieron una pelicula, que la compraron, etc, en lugar de en la puntuación. Aquí es donde entra en juego nuestra imaginación.
Problemática del Filtrado Colaborativo aplicado a usuarios
En esta técnica, como habréis podido imaginar, hay una serie de problemas que enfrentaremos:
- Debido a que puede existir una cantidad gigantesca de usuarios, la matriz puede tener una dimensión tremenda, lo que implica un coste computacional muy grande que requerirá de técnicas específicas para ser manejada y procesada.
- Los gustos de los usuarios pueden cambiar en el tiempo, y ya que la matriz no recoge estos “cambios”;, en principio podríamos estar recomendando productos basándonos en una similaridad temporal. Por ejemplo, ¿que pasa si una persona compra muchos videojuegos, y un tiempo después tiene hijos, y empieza a comprar pañales y ropa de bebe? Podría ocurrir que otro usuario que disfruta de los mismos juegos que este “usuario padre”; jugó, ahora empiece a recibir recomendaciones con las mejores marcas de pañales.
- Los intereses ocultos también pueden jugar una mala pasada, de hecho hay un tipo de ataque (shilling attack, aunque yo prefiero llamarlo simplemente troleo profesional), que consiste en que un usuario que pueda tener interés por que un producto se recomiende para potenciar su venta, comience a registrarse con usuarios falsos para valorar numerosas veces ese producto con 5 estrellas, o al reves, para penalizar a la competencia. Esto por supuesto puede aplicarse con técnicas mucho mas avanzadas.
Variación: Filtrado colaborativo de productos (Item-based Collaborative Filtering)
Para aplacar los problemas anteriores, es posible utilizar una variación del sistema basado en usuarios, que consiste precisamente en basar las recomendaciones en la similaridad entre los productos (items).
Haciéndolo de este modo el problema se resuelve de forma más sencilla, ya que probablemente tendremos menos productos que usuarios (o eso desearíamos) lo que hace que el problema sea más manejable en términos de computación.
También se evita en gran medida el hecho de que el usuario cambia con el tiempo (su personalidad, etc.) ya que los productos serán idealmente los mismos (no obstante el problema no desparece, ya que las tendencias si cambian, la forma en que los productos son percibidos debido al contexto cultural, socioeconomico… etc. pero dado que la existencia del producto suele ser mas corta, es más fácil de manejar a otros niveles).
También será más difícil que los usuarios desarrollen técnicas para “piratear”; o “trolear”; nuestro motor de recomendación, ya que no bastará con crear usuarios y ponerse a valorar productos específicos… de hecho, es recomendable basar las recomendaciones en las compras de los usuarios (en lugar de en los productos que ven, añaden a la cesta, etc.) ya que de este modo es necesario “pagar”; para poder engañar al sistema, y este se vuelve más robusto y fiable (o al menos el proceso deja algún beneficio ;-D ).
Una forma de diseñar este filtrado colaborativo basado en productos, sería algo así como encontrar todos los pares de productos que un usuario compró, entonces mediríamos la similaridad de las valoraciones de ese par de producto para cada usuario que los compró, y entonces ordenaremos por productos y por esta “similaridad”;.
Por ejemplo, podríamos coger cada par de productos que un usuario ha comprado, por ejemplo un Razer Keyboard y un Razer Mouse, y buscar cada usuario que tambien compró el mismo par. Entonces, medimos las puntuaciones que ambos productos han recibido, y si son similares para la media de todos los usuario, significa que estos productos son similares, independientemente de quien los comprase. Si ahora cogemos Razer Keyboard y ordenamos el resto de productos (con los que comparte par) por esta similaridad, podemos obtener los más parecidos a él, o algo como “a la gente que le gustó esto tambien le gustó esto otro”;.
Es importante destacar en este punto que una puntuación alta para ambos significa que se parecen… pero tambien significa lo mismo una puntuación baja para ambos. Lo que interesa, de hecho, es únicamente el parecido en este “score”; asignado a cada producto, no si es alto o bajo.
Ejemplos en Python
He dicho que vamos a ver algún ejemplo en Python, y así es; para ello vamos a utilizar alguno de los datasets que se encuentran disponibles en MovieLens.org, donde hay un monton de información sobre peliculas, así que podemos experimentar con estos datasets.
Para ello, descargaremos los ficheros de GroupLens.org (por ejemplo el de 100k registros) y los almacenaremos en alguna carpeta local. Vamos a ello.
Encontrar películas similares
Primero cargamos los datasets de los que hablaba:
import pandas as pd
r_cols = ['user_id', 'movie_id', 'rating']
ratings = pd.read_csv('D:/Cursos/DataScience/Resources/ml-100k/u.data', sep='\t', names=r_cols, usecols=range(3), encoding="ISO-8859-1")
m_cols = ['movie_id', 'title']
movies = pd.read_csv('D:/Cursos/DataScience/Resources/ml-100k/u.item', sep='|', names=m_cols, usecols=range(2), encoding="ISO-8859-1")
# combinamos ambos datasets para tener el
# usuario, la pelicula, la puntuacion que asignó y el titulo
ratings = pd.merge(movies, ratings)
# Pivotamos esta tabla para crear una matriz que tiene
# una fila por cada usuario
# una columna por cada pelicula
# en la celda que se cruzan esta la puntuacion que le dio, si es que la valoró
movieRatings = ratings.pivot_table(index=['user_id'],columns=['title'],values='rating')
movieRatings.head()
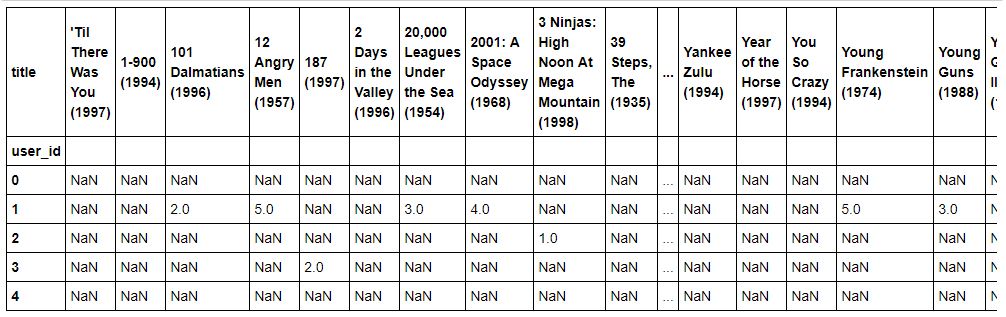
Usuarios / Pelicula
Si quisiéramos hacer filtrado colaborativo por usuarios, tendriamos que coger al usuario (es decir, una fila) pero como lo queremos hacer por productos (items, o en este caso películas) hay que coger columnas, y correlarlas entre sí. En este caso vamos a buscar la columna de Toy Story, ya que vamos a buscar peliculas parecidas a ella.
toyStoryRatings = movieRatings['Toy Story (1995)']
# Correlamos el resto de peliculas (columnas) con la seleccionada (toy story)
similarMovies = movieRatings.corrwith(toyStoryRatings)
similarMovies = similarMovies.dropna()
df = pd.DataFrame(similarMovies)
# Las ordenamos por el valor de score que hemos generado, de forma descendente
similarMovies.sort_values(ascending=False)

Películas similares
Como podemos ver, hay muchas películas con máximo nivel de parecido (similarity score) pero sin embargo son muy desconocidas. Esto se puede producir si estamos basando el parecido en muy pocos usuarios (pocos casos), ya que por ejemplo, un solo usuario que haya visto Toy Story y Phantoms puede haber asignado la misma puntuación a ambas, pero eso no quiere decir que sea idéntica, y mucho menos que el resto de usuarios piensen igual.
Para solucionarlo, lo que haremos será agregar las votaciones por película (independientemente del usuario) para coger solo aquellas peliculas que tengan al menos 100 valoraciones de usuarios distintos. Esto es una aproximación para resolver el problema, podría haber otras, o usar distintos valores de threshold para el número de puntuaciones.
import numpy as np
# agregamos por titulo y devolvemos el
# numero de veces que se puntuo, y la media de puntuacion
movieStats = ratings.groupby('title').agg({'rating': [np.size, np.mean]})
# nos quedamos con todas las que tengan mas de 100 puntuaciones
# de distintos usuarios
popularMovies = movieStats\['rating'\]\['size'\] >= 100
# ordenamos por la puntuación asignada
movieStats[popularMovies].sort_values([('rating', 'mean')], ascending=False)[:15]
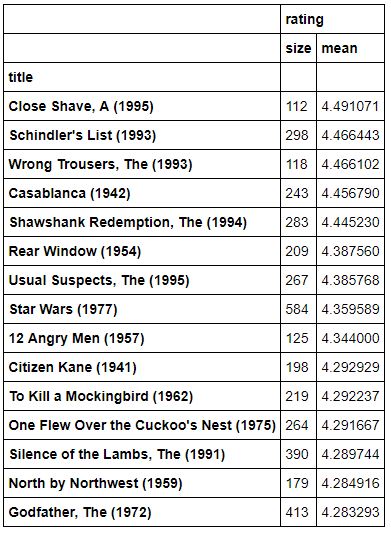
Puntuaciones películas
Podemos ver todas aquellas peliculas que tienen más de 100 valoraciones de distintos usuarios, ordenadas por su puntuación media. Si ahora hacemos un “join”; con la tabla de votos original, nos quedaremos solo con estas peliculas, descartando aquellas que solo votaron unos pocos usuarios:
# hacemos el join
df = movieStats[popularMovies].join(pd.DataFrame(similarMovies, columns=['similarity']))
# Ordenamos el dataframe por similaridad, y vemos los primeros 15 resultados
df.sort_values(['similarity'], ascending=False)[:15]
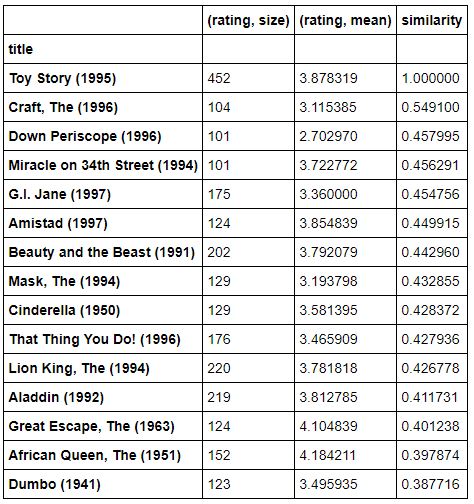
Similares a Toy Story
Si nos fijamos en los resultados, ahora que estamos filtrando por peliculas donde hay un mayor volumen de valoraciones y por lo tanto estamos aumentando la credibilidad de la puntuación media asignada, veremos que empiezan a tener más sentido, hay otras peliculas infantiles como Aladdin y Dumbo, que seguramente gustaron bajo los mismos parámetros que Toy Story. Estas películas si empiezan a ser buenas recomendaciones para nuestros usuarios que hayan visto Toy Story pero no alguna de las otras películas.
Construir el motor de recomendación
Ahora que hemos visto un ejemplo de como encontrar similaridades entre peliculas, podemos avanzar y tratar de generar recomendaciones para un usuario basadas en su actividad anterior (en su histórico de puntuaciones). Es muy parecido a lo que hemos hecho hasta ahora… esta vez lo que haremos será, en lugar de correlar la pelicula Toy Story con las demás, correlar todas con todas, del siguiente modo:
# correlamos todas las columnas con todas las demás
# usamos el metodo pearson
# descartamos todas aquellas que no tengan al menos 100 valoraciones de usuarios
corrMatrix = userRatings.corr(method='pearson', min_periods=100)
corrMatrix.head()
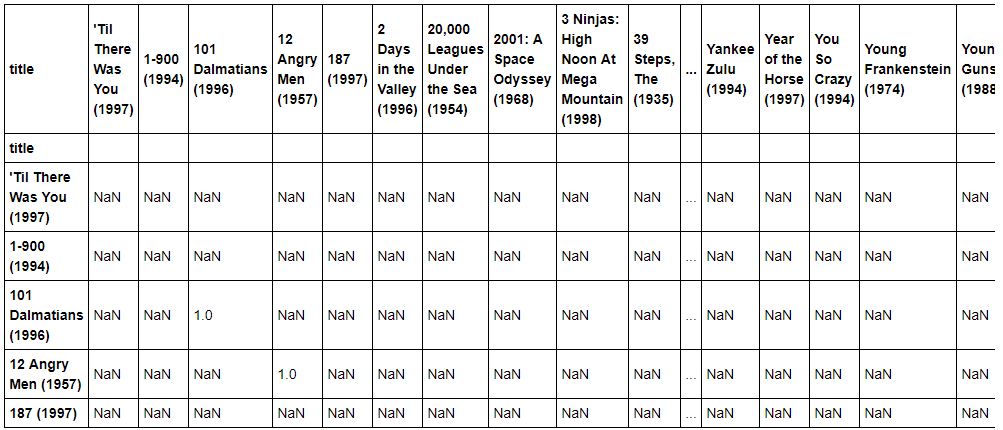
Correlación Todas con todas
En el cuadro anterior podemos ver algunos de los resultado. Cada celda representa lo que una pelicula se parece a otra. En aquellas que hay NaN quiere decir que no se cumplia nuestra restricción minima, es decir que no había 100 votaciones para ese par, por lo que no hay un resultado para el cálculo. En las que aparece un 1, es que son identicas, algo que ocurre en todas las peliculas (en este caso en todas las que tienen al menos 100 votaciones). Es una tabla sparse (con muchos nulos), pero en algunas celdas habrá valores decimales que indican el parecido entre ambo par de películas.
Ahora vamos a escoger un usuario cualquiera, y a generar recomendaciones basado en lo que ha visto:
# seleccionamos el usuario 105
# y eliminamos todas las columnas que tengan nulo (peliculas no vistas)
myRatings = userRatings.loc[105].dropna()
# vamos a echar un vistazo a lo que ha puntuado este usuario
myRatings
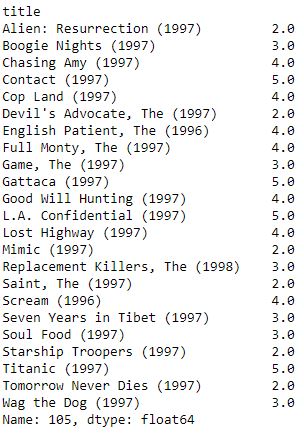
Películas que vió el usuario
En los resultado anteriores vemos que el usuario es un aficionado la ciencia ficción y que le gustan mucho peliculas como Contact o Gattaca, aunque tambien Titanic, así que parece que el drama y la ciencia ficción son lo suyo. Vamos a ver qué otras películas podemos recomendarle…
Lo que haremos para ello será, para cada pelicula que el usuario ha puntuado, cogeremos todas peliculas similares según nuestra matriz de similaridad anterior. Para evitar que le recomendemos simplemente peliculas parecidas, y le mostremos peliculas que parecidas QUE LE GUSTARÁN, lo que haremos será potenciar el valor de correlación entre películas en función de la valoración que el usuario asignó a las que vió, multiplicando la puntuación del usuario por la correlación del par de películas. De este modo, además, las peliculas que no le gustaron (como Tomorrow Never Dies) hará que las peliculas parecidas tengan peor puntuación.
posiblesSimilares = pd.Series()
# Recorremos las peliculas valoradas por el usuario
for i in range(0, len(myRatings.index)):
print ("Similares a " + myRatings.index[i] + "...")
# Obtenemos peliculas similares a esta que el usuario ha puntuado
sims = corrMatrix[myRatings.index[i]].dropna()
# Multiplicamos el score de correlacion por la puntuación asignada por el usuario
sims = sims.map(lambda x: x * myRatings[i])
# Añadimos la pelicula y la nueva puntuacion a nuestra lista de candidatos
posiblesSimilares = posiblesSimilares.append(sims)
# Agrupamos los resultados, ya que si una pelicula es parecida a dos de las
# que ha visto el usuario, aparecerá dos veces
# podríamos agrupar haciendo la media de puntuación, o como en este caso
# sumandolo, ya que si aparece dos veces será porque es una pelicula
# muy recomendable... y así saldrá la primera. Va en cuestión de gustos.
posiblesSimilares = posiblesSimilares.groupby(posiblesSimilares.index).sum()
# Finalmente filtramos todas aquellas peliculas que el usuario ya habia valorado
# puesto que no tiene sentido que se las recomendemos si ya las ha visto
# le decimos que ignore errores para evitar excepciones si hay problemas
# con el CharSet de los titulos
filtered = posiblesSimilares.drop(myRatings.index,errors='ignore')
filtered.head(10)
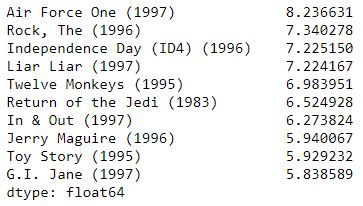
Recomendación final
Y este es nuestro resultado, le recomendaremos películas como Independence Day, el Retorno del Jedi, y algún que otro dama. Películas que el usuario no ha visto y que probablemente podrían gustarle basándonos en su actividad anterior.
Aún habría mucho que experimentar aquí, pero está claro que para el esfuerzo que ha supuesto crear este sistema… es un gran resultado.
¡Espero que os haya gustado!