Ultimamente en los proyectos en el trabajo siempre algo puede mejorar incluyendo modelos de IA, cuando estoy liado con el desarrollo de videojuegos, hay Inteligencia Artificial, y cuando veo publicaciones de artistas gráficos en Instagram ¡también emplean la IA!
Está claro que está por todas partes, así que he pensado en hacer un repaso de los conceptos y técnicas fundamentales que mejor conozco, a modo de guia de por donde empezar, y que pueda servirme tanto a mi para poner algo de orden en la cabeza, como a ti, ¡si es que andas investigando sobre el tema!
Índice de la serie de artículos
Iré actualizando esta sección a medida que vaya escribiendo más capítulos sobre el tema
- Introducción y clasificación
- Flujo de trabajo
- Validar el modelo
- Análisis exploratorio
- Algoritmos de Machine Learning:
- Supervisado:
¿Qué es la Inteligencia Artificial (IA)?
Es el término por el que habitualmente se denomina a la tecnología que permite que una máquina “imite” comportamientos y capacidades consideradas humanas.
Estas tecnologías mejoran y aumentan en posibilidades día a día, aunque desde algunos titulares de prensa, hasta el cine y los libros han creado un caldo de cultivo en el que parece que una IA fuese capaz de cualquier cosa, la realidad es muy diferente, y de hecho actualmente su principal beneficio es el de complementar la labor de los humanos apoyando en tareas de análisis, complejas o bien repetitivas, por ejemplo, para realizarlas más eficazmente. Esto no quita, sin embargo, que en ocasiones su uso no llegue a ser absolutamente sorprendente, y que su potencial a largo plazo sea prácticamente inconcebible.
Clasificando la Inteligencia Artificial
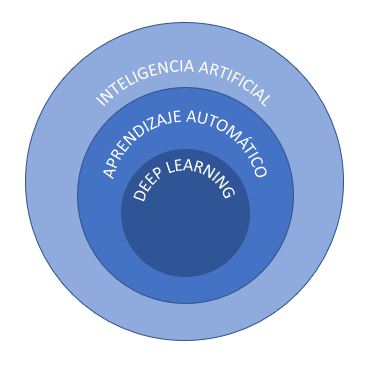
Más allá del uso del término de forma general, la Inteligencia Artificial se divide y clasifica de diversos modos, y aparecen nuevos terminos relacionados pero más especificos que te podrán sonar, como Machine Learning (Aprendizaje Automatico) o Deep Learning (Aprendizaje profundo o Redes Neuronales):
- Artificial Intelligence (AI): Cualquier técnica que permita a las computadores imitar inteligencia humana, utilizando reglas lógicas, reglas si-entonces…, árboles de decisión, aprendizaje automático o aprendizaje profundo.
- Machine Learning (ML): Subconjunto de la IA que se centra en el uso de técnicas estadísticas para permitir a las máquinas mejorar en la realización de tareas en base a su experiencia anterior.
- Deep Learning (DL): Subconjunto del ML que se compone de algoritmos que permiten a un software entrenarse a si mismo para la realización de tareas, como hablar o reconocer imágenes, mediante el uso de redes neuronales multicapa e importantes cantidades de datos para su entrenamiento.
Considerando su aplicación
La Inteligencia Artificial también se cataloga a menudo en base al objetivo de su aplicación, no solo de a las técnicas empleadas. Generalmente un tipo de problema requerirá de técnicas apropiadas para su resolución, por lo que cada una de las técnicas anteriores puede relacionarse con cada aplicación. Sin embargo, esto no impide que para un caso puedan combinarse entre si, ni garantiza que la tecnología que hoy resulte más adecuada vaya a seguir siéndolo en el futuro.
Si ampliamos el arbol anterior incorporando aplicaciones posibles, podemos construir un diagrama como este:
- Inteligencia Artificial
- Machine Learning
- Natural Language Processing (NLP)
- Extracción de contenidos
- Clasificación
- Traducción automática
- Búsqueda de respuestas
- Generación automática de textos
- Visión
- Reconocimiento de imágenes
- Visión artificial
- Speech
- Texto a voz (sintetizadores)
- Voz a texto
- Planning
- Robótica
- Sistemas expertos
Ramas principales y usos
A continuación vamos a hacer un repaso general por los usos más habituales de la Inteligencia Artificial.
Machine Learning
Como hemos visto antes, esta rama de la IA se centra en el uso de técnicas estadísticas de menor o mayor complejidad para desarrollar algoritmos capaces de reconocer patrones o características de la información de la que se disponga. Esta información se puede utilizar para entender conjuntos de datos, ayudar en la interpretación de información, optimizar procesos, inferir nuevas características o datos, clasificar, etc.
Cuando se habla de Inteligencia Artificial, en muchos casos se está hablando en realidad de Machine Learning, ya que es el área con un uso más extendido actualmente. Las matemáticas en las que el Machine Learning se apoya no son nuevas ni mucho menos, pero es ahora cuando existe un caldo de cultivo adecuado para la democratización de su uso: cada vez es más habitual y facil recabar y almacenar datos que alimentarán a estos algoritmos, las computadoras que tenemos por casa son capaces de ejecutar los cálculos necesarios en tiempos viables para su explotación, existen librerias y servicios que facilitan muchísimo su uso incluso “sin tener ni idea” de matemáticas, etc.
Por la naturaleza de las técnicas subyacentes, es habitual que la mayoría de tecnicas de Machine Learning requieran de grandes cantidades de datos para su entrenamiento antes de arrojar resultados satisfactorios. Pero no es suficiente con tener un gran número, sino que se requiere calidad en los mismos: estos deben ser relevantes, estar balanceados, normalizados, completos, etc.
Deep Learning
Dentro del Machine Learning tenemos esta rama más compleja aunque de uso cada vez más frecuente gracias a sistemas como TensorFlow que han acercado estas técnicas a perfiles no tan especializados. Consisten en la construcción y entrenamiento de redes neuronales de múltiples capaz que permiten clasificar datos o detectar anomalías en patrones.
A menudo se comete el error de pensar que el Deep Learning o las Neural Networks son las adecuadas para resolver cualquier tipo de problema, o que es a esto a lo que realmente se refiere el término Inteligencia Artificial, pero lo cierto es que generalmente los problemas pueden ser resueltos de distintas formas, y no hace falta implemenentar redes neuronales en la mayoria de los casos, ya que suelen ser computacionalmente mucho más costosas que las técnicas de ML que podrían incluso arrojar mejores resultados. Sin embargo, hay ciertas situaciones en las que utilizar técnicas estadísticas sobre conjuntos demasiado grandes de datos, o donde otras tecnicas no son aplicables, las redes neuronales pueden alcanzar resultados soprendentes.
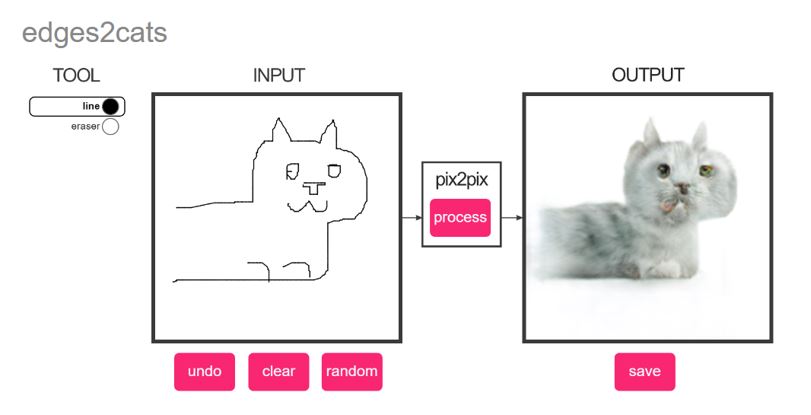
Hay también variaciones de las redes neuronales que se utilizan para diversos fines y que a menudo acaparan los titulares por su atractivo, como es el caso de las Redes Neuronales Generativas Adversarias (GANs), entre tantas otras, que por ejemplo son capaces de generar por si mismas nuevos contenidos, como rostros artificiales, fotografias reales a partir de bocetos, o paisajes.
Algoritmos de aprendizaje Supervisado
Cuando se habla de aprendizaje automático supervisado, se está haciendo referencia a la rama de técnicas del ML en las que el entrenamiento se lleva a cabo mediante conjuntos de datos en los que existen tanto las características de los propios datos, como las respuestas que se están buscando (etiquetas / outputs). Los algoritmos de aprendizaje supervisado buscan las relaciones entre las caracteristicas de cada registro observado en el conjunto de datos y su etiqueta asignada (manualmente por un humano, por ejemplo), de manera que, cuando después del entrenamiento se le entregue una nueva observación en la que la etiqueta no se conoce, sea capaz de inferirla a partir de únicamente sus características.
Un ejemplo cualquiera sería el del calculo de precio de un vehiculo. Se entrenaría el algoritmo con una bateria de observaciones (datos de vehículos) donde para cada uno se conocen sus caracteríticas (cilindrada, acabados, tipo de vehiculo, combustible, etc) y su etiqueta (en este caso el precio de mercado). Posteriormente, a partir de la información de su cilidrada, acabado, combustible, etc, de un nuevo vehiculo, podríamos calcular su precio de mercado si no lo conocemos.
Estos algoritmos se dividen en varios tipos, los dos más comunes son:
- Regresión: La salida que se desea calcular es un número, por ejemplo el caso anterior, el precio del coche.
- Clasificación: La salida es una etiqueta que permite clasificar elementos en grupos (por ejemplo, caro/barato)
Estas técnicas (y otras, o en combinación de otras) pueden ser aplicadas para realizar predicciones:
- Análisis predictivo: especialmente cuando una de las dimensiones es el tiempo, se pueden emplear tecnicas de analisis de series temporales mono o multivariante para “predecir el futuro” más probable, ya sea conociendo el historial previo e ir calculando la secuencia posterior hasta un determinado momento, o dada una hipotesis especifica para un momento concreto.
- Sistemas de recomendación: Cuando se conocen las preferencias de los usuarios ante ciertos contenidos, o las acciones que han realidado en un contexto concreto, es posible predecir como se comportará ese usuario (o usuarios similares) basandonos en este comportamiento pasado. Esto sirve de base para construir sistemas de recomendación de distinto tipo, como los clasicos “Productos comprados habitualmente juntos”, o la recomendación de una serie en base a valoraciones de series vistas anteriormente.
Hay muchos ejemplos de aprendizaje supervisado que intervienen en nuestra vida cotidiana. Otro ejemplo clásicó sería el del algoritmo de recomendación de Netflix, que utiliza varías técnicas para predecir si una película te gustará o no, en base al tipo de contenido que sueles consumir, cuándo y como lo haces, las valoraciones que dejas, las características de una pelicula que nunca has visto, lo que otros usuarios similares a ti (que esto es otro mundo también) opinan de ella, etc.
Algoritmos de aprendizaje No Supervisado
En los algoritmos de aprendizaje no supervisado, a diferencia del caso anterior, no se dispone de las etiquetas durante su entrenamiento, sino únicamente de sus características. Puede que no se tengan esas “etiquetas” porque nadie las haya introducido, o es que directamente aún no las conozcamos.
Estos algoritmos agrupan las observaciones identificando patrones o similitudes entre ellas, de manera que las que están “más cerca” entre sí, formarían un “cluster” o conjunto de datos que, en principio, podrían representar una categoría especifica de nombre desconocido que debemos bautizar y será entonces trabajo de un experto humano en ese dominio determinar qué categoría está reconociendo el algoritmo. En procesos automatizados, podría no ser necesario dar un nombre concreto a cada categoría, sacando partido del hecho de que, independientemente de lo que represente, los elementos que pertenezcan al mismo cluster recibirán un tratamiento similar por parte del sistema.
Estos clústeres podrían crearse en función de cómo de parecidos o diferentes permitamos que sean entre sí, con lo que se encontrarían un número diferente de conjuntos, o incluso organizadas en dendrogramas si es que creemos que existen jerarquías en nuestros datos.
Algoritmos de aprendizaje por refuerzo
Estos métodos se basan en los princpios de la psicología conductista para entrenar algoritmos automaticamente sin la necesidad de datos previos. En lineas generales, consiste en establecer una serie de reglas de accion o comportamiento, y un entorno, en el que se ubica un agente. El agente realizará acciones de entre las posibles, y un observador externo medirá los resultados, dando una mayor puntuacion cuando estos se acerquen a los objetivos que se pretendan. El resultado obtenido se incorpora como observación al modelo de aprendizaje automatico del agente, programado para maximizar la recompensa. A medida que se ejecutan innumerables ciclos, el agente estará cada vez mejor entrenado, y tomará mejores decisiones, descartando aquellas acciones que no conduzcan al objetivo deseado.
Esta técnica es sin duda mi favorita, me quedo hipnotizado viendo ejemplos porque además son siempre muy entretenidos. En este canal, por ejemplo, simulan una versión simplificada de la selección natural, ¡echale un ojo!
Natural Language Processing (NLP)
El procesamiento de lenguaje natural se refiere a las técnicas que permiten que una máquina entienda las palabras y textos, ya sean de forma escrita, impresa o hablada, en el lenguaje utilizado por los humanos de manera natural (sin emplear comandos o lenguajes específicos que faciliten la interpretación por parte de la computadora).
Esta es la tecnología que se emplea en los Chatbots (en los buenos), pero también en muchos otros campos, como por ejemplo analizar el contenido de los emails para identificar si se trata o no de Spam, o para hacer resúmenes de libros.
Dentro de las ténicas de NLP, existen una gran diversidad de subconjuntos de tecnicas y aplicaciones posibles, por ejemplo:
- Generación automática de textos o Generación de lenguaje natural (NLG): se centran en dotar al software de capacidad para tomar decisiones acerca de como un concepto específico puede ser espresado mediante palabras en lenguaje natural, completar frases, corregir textos, etc.
- Chatbots: Se emplean diversas técnicas combinadas, pero el NLP tiene un papel relevante ya que permite analizar los objetivos del usuario en la comunicación y sintetizar su intención y los parámetros o entidades reveladas en la conversación. Por ejemplo, cuando un usuario le dice al chatbot “buenos días, me gustaría alquilar un piso en Madrid por 750€ al mes”, los algoritmos identificarán “alquilar” como intención, y “zona=Madrid” y “precio=750” como parámetros de entrada, que serán entregados a un software tradicional para que realice las búsquedas oportunas.
Si quieres flipar un poco con lo que estos sistemas son capaces de hacer, echa un vistazo a esta entrevista que hicieron a GPT-3 donde la propia IA opina que no cree que vaya a sustituir las capacidades humanas (curiosa forma de demostrarlo).
Aunque en realidad GPT-3 es más “clasificable” como Deep Learning que como NLP, es evidente que hay capas en las que el procesamiento del lenguaje natural es evidente, más allá de cual sea la técnica empleada, y es que como decía antes, es muy habitual combinar muchas estrategias en cada capa de un sistema de Inteligencia Artificial para lograr resultados adecuados, por lo que la clasificación del sistema es un tanto difusa.
Visión artificial o computacional
La visión artificial o computacional son las técnicas y métodos que permiten a una máquina adquirir, procesar y analizar las imágenes que provienen del mundo real y producir información y datos a partir de ellas.
En general una misma imagen se descompone y se realizan distintos análisis en busca de diferentes rasgos y patrones, que son los que se usan para generar la nueva información.
La vision artificial puede combinar numerosas técnicas de la IA y sus aplicaciones son muy amplias: reconocimiento de objetos o reconocimiento facial, identificacion de personas, detección de objetos en la escena, detección de movimiento o actividades, reconstrucción de escenas, etc.
También interviene en muchos otros usos, por ejemplo, la tecnología NERF combina muchas técnicas para virtualizar objetos y espacios en 3D, con un propósito similar al de la fotogrametría, pero con unos resultados alucinantes.
Otro ejemplo aunque sea un poco de soslayo (pero permiteme que busque más la inspiración que la ortodoxia en la clasificación) es el de Dall-E 2, no dejes de echar un vistazo a esta IA capaz de crear imagenes realistas de conceptos que no existen y que nunca ha visto antes. ¿Quieres una imagen de un astronauta montando en unicornio en un planeta con la forma de un aguacate y con el estilo de dibujo de Frank Frazetta? ¿O una imagen de dos osos de peluche cientificos mezclando componentes químicos chispeantes y disfrazados de cientifico loco estilo steampunk? ¡simplemente pídeselo!. Si no estamos viviendo en el futuro, no entiendo nada.

Speech
Se conoce así a las técnicas de IA aplicadas a la generación de voces sintéticas (Texto a voz), como por ejemplo la voz sin género Q o las voces que nos hablan desde los asistentes de voz como Alexa, Siri o Google.
También se incluyen en esta categoría las tecnicas que permiten la acción inversa, es decir, identificar la voz humana y reconocer las palabras a partir de los sonidos (Voz a texto).
Flujo de trabajo
En el siguiente artículo puedes continuar la lectura, esta vez sobre el flujo de trabajo y los ingredientes principales para desarrollar un sistema de Inteligencia Artificial.