En este post voy a intentar resumir brevemente cuales son los los ingredientes y los pasos principales a considerar cuando trabajamos con IA. Es el segundo de los dos articulos introductorios teóricos antes de adentrarnos en cuestiones más técnicas.
Índice de la serie de artículos
Iré actualizando esta sección a medida que vaya escribiendo más capítulos sobre el tema
- Introducción y clasificación
- Flujo de trabajo
- Validar el modelo
- Análisis exploratorio
- Algoritmos de Machine Learning:
- Supervisado:
Ingredientes principales
Los ingredientes principales para trabajar con IA serán los siguientes:
- Datos: En la mayor parte de los algoritmos que emplearemos vamos a necesitar datos. Generalmente una GRAN CANTIDAD de datos. El éxito de la aplicación de la IA actualmente se debe, al menos en parte, a que durante años ha sido posible trabajar en la recopilación de bastas colecciones de datos desde el boom del Big Data. La cantidad y el tipo de datos necesarios dependerá de los algoritmos que vayamos a utilizar. Lo veremos más adelante.
- Orígenes y almacenes de datos: Todos esos datos que alimentarán a nuestros algoritmos, o los que nuestros modelos y procesos produzcan en fases intermedias o como resultado, deben estar disponibles o almacenarse en algun sitio. Aqui es donde entran los Data Lakes y las Data Warehouses.
- Modelos y algoritmos: Lógicamente necesitaremos escoger o diseñar algoritmos o modelos que serán los que a partir de los datos de entrada produzcan resultados que respondan a nuestras necesidades.
Datos
Generalmente, cuando hablamos de datos, estos pueden estar en distintos formatos, desde no estructurados (imágenes, videos, audios, pdf…), hasta completamente estructurados (ficheros JSON, CSV, etc.). Generalmente en algún punto intermedio de nuestro flujo de datos, como veremos más abajo, habrán sido adecuadamente preparados, y dispondremos de uno o varios datasets (tablas de datos con numerosos registros). Algo como lo siguiente:
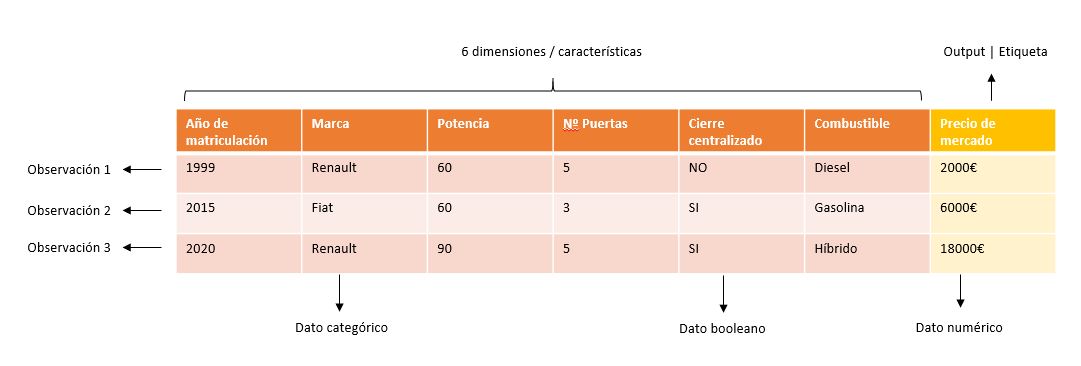
Perfiles
En función de cuales sean los ingredientes con los que trabajamos, nos especializaremos en un área en particular. De esas especializaciones es de donde surgen nombres tan rimbombantes como algunos de los siguientes:
- Científico de datos (Data Scientist): requiere un conocimiento relativamente profundo de de matemáticas, estadística y quizá un poco menos de programación. Se encarga de diseñar los algoritmos y modelos de IA, ML, DL, etc. para obtener resultados lo más precisos posibles. Los problemas que resuelven suelen ser muy concretos, y cada uno requiere un análisis profundo, numerosas iteraciones de implementación y pruebas, y mucho tiempo. Su labor exige conocer el estado de la técnica para elegir las soluciones más adecuadas y poder ajustar adecuadamente los métodos.
- Analista de datos (Data Analyst): se centra fundamentalmente en el reporting, generación de informes y paneles de control (dashboards). Sus skills se relacionan con las herramientas de mineria de datos para realizar tareas de BI probablemente con algun producto específico para ello, por lo que en pocas ocasiones entienden los detalles de la implementación con la obtienen la información o entran a ajustar parametros. Generalmente requiere menos conocimientos que los del Data Scientist.
- Ingeniero de datos: normalmente se centran en la manipulacion de los datos y los almacenes de datos. Diseñan y construyen las soluciones que permiten la ingesta, el almacenamiento y la consulta de cantidades de datos que pueden exigir tecnologías propias del Big Data (HDFS, Apache Spark, Hadoop, almacenamiento distribuido, bases de datos NoSQL y SQL).
- Experto en el campo: Tanto los Data Scientists, como los Data analysts, e incluso los directivos que utilicen los informes para la toma de decisión o que encarguen los trabajos en primer lugar, necesitarán en algun momento de la colaboración con un experto en el sector o en el dominio concreto en el que se esté trabajando. Sin su ayuda, las conclusiones obtenidas pueden ser erroneas en cualquiera de las etapas, ya sea malinterpretando los datos en crudo, en las graficas resultantes, o en la aplicación de las conclusiones.
Flujo de trabajo y pipeline.
El flujo de trabajo realmente depende mucho del tipo de trabajo a realizar y de las necesidades que tengamos en cada caso. Por esto no voy a entrar en detalles de cada punto, pero sí a dejar algunas buzzwords y a enumerar las fases importantes, ya que a menudo comparten ciertas similitudes. El caso que se ve más habitualmente es el del flujo de datos empleado en Business Intelligence (BI), algo así:
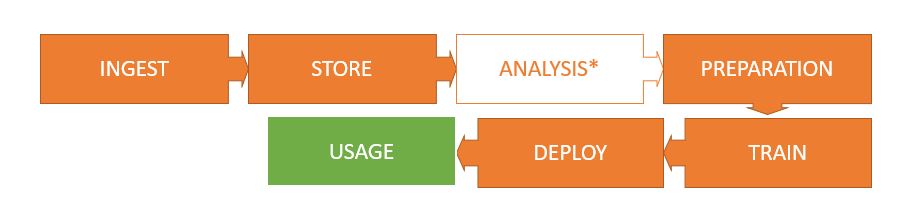
- Ingesta (Ingest): Los datos con los que trabajaremos generalmente estan repartidos por varios sitios e incompletos en cada uno (silos de datos). Por ejemplo, si quisieramos saber el estado de ánimo de los compradores de un e-commerce al escribir las reviews, y contrastarlo con el estado de animo de la gente de la zona que no son compradores, y ver si está afectado por el clima, necesitariamos recopilar informacion de twitter, de las reviews del software de e-commerce de la empresa, de las compras y donde se produjeron, y de algun servicio de información meteorológica de terceros. La ingesta son las técnicas y tecnologías implicadas en obtener toda esta información, ya sea en diferido o en tiempo real, e introducirla a nuestro flujo de trabajo (pipeline).
- Almacenamiento (Store): Los datos recabados en el proceso de ingesta se almacenan entonces en sistema de almacenamiento para hacerlos facilmente disponibles para los trabajos posteriores (Data Lake). En este paso, el sistema de datos suele ser un NoSQL que contendrá datos semiestructurados, estructurados y no estructurados. Aunque tambien puede componerse de varios almacenamientos, el primero de ellos con los datos en crudo tal cual se obtuvieron (Raw Data) y el último donde haya habido cierto procesamiento (limpieza, desambiguación, eliminar duplicidades, composición y enriquecimiento). Es recomendable no perder los datos originales, especialmente si estamos realizando y almacenando tambien manipulaciones, por si los necesitasemos en el futuro.
- Análisis: El científico de datos, antes de escoger los algoritmos que se emplearán, necesita conocer el material con el que trabajará. En este punto se realiza un analisis exploratorio de los datos con el propósito de comprenderlos, identificar sesgos (bias), datos faltantes (sparse data), tipología, número de dimensiones, y en general comprender la calidad de los datos de partida. Es bueno trabajar con un experto en el sector para una mejor comprensión. Este es un proceso manual y forma parte del pipeline automatizado que sera el resultado del trabajo.
- Preparación: Una vez se han entendido los datos, y se tiene una idea de qué algoritmos se aplicarán, es necesario preparar los datos de Data Lake para que resulten compatibles con estos. Esto implica eliminar características innecesarias, normalizar datos, convertir columnas numericas y categóricas, transformar tipos de datos, combinar datasets… Este proceso tambien se conoce como Data Wrangling.
- Train: Cuando los datos están preparados, se utilizan para entrenar los modelos de aprendizaje que se hayan escogido. Este proceso puede ser exigente computacionalmente en función del tipo y volumen de datos y de los algoritmos que se empleen.
- Despliegue (Deploy): los modelos entrenados se despliegan en forma de servicios accesibles desde el exterior, o bien se introducen conjuntos de datos con observaciones nuevas y se publican los resultados obtenidos de los modelos en algun formato que resulte conveniente.
- Explotacion (Usage): El Analista de datos genera informes o paneles de control (dashboards) con gráficos que permitan una rápida comprensión y generación de conclusiones de las preguntas que fuesen originalmente planteadas por los interesados (stakeholders). Un experto en el sector podría intervenir para profundizar en la comprensión de la información. Tambien es posible en este punto integrar esta información con otras aplicaciones o servicios para emplearla en otros procesos de negocio.
Calidad vs cantidad de datos
Como ya sabes, muchos de los algoritmos que se emplean en IA exigen grandes cantidades de datos para un correcto entrenamiento. Es posible que un mayor número de datos permitan generar mejores modelos y resultados más precisos y completos. En algunas ocasiones, sin embargo, esto puede no ser así, y un gran número de datos puede ser suponer un coste computacional innecesario, o incluso ser contraproducentes.
En cualquier caso, una vez que comprendermos las características de nuestros datos, y el funcionamiento de los algoritmos que vamos a aplicar, debemos disponer de al menos la cantidad suficiente de datos para ese caso, ya que si estamos por debajo, lo mas probable es que los resultados del modelo sean prácticamente aleatorios o incluso peores.
Sin embargo, además de cantidad de datos, necesitaremos que estos sean de calidad. De hecho, la calidad de los datos es más importante que su volumen. Un pequeño conjunto de datos de alta calidad permite generar mejores modelos de aprendizaje que una gran cantidad de datos de poca calidad.
Para que los datos sean de calidad, estos deben ser representativos, completos y significativos. Además deberían estar equilibrados (es decir, no sesgados), y por supuesto deben ser correctos (no contener errores).
Consideraciones éticas
No solo los datos deben cuidarse de cara a que los modelos sean precisos y funcionales para nuestros propósitos, sino que los individuos y las empresas deberían ser responsables de hacer un uso ético de los mismos.
Son numerosos los ejemplos de casos reales en los que un conjunto de datos sesgado ha generado problemas para un género, étnia, religión o grupo de edad, simplemente por una cuestión de que existian un menor numero de muestras para el grupo minoritario, siendo perjudicado y en algunos casos con resultados realmente lamentables.
Los datos, los modelos y el uso que se hace de su explotación debe cuidarse, especialmente cuando puedan estar provocando el sostenimiento (o incluso empeorar) una situación injusta. Cuando la realidad es injusta, los datos que empleamos reflejarán esta injusticia y no por ello las muestras dejan de ser objetivas y correctas, sin embargo será nuestra labor ocuparnos de que nuestros modelos estén libres de estos defectos. Por ejemplo, si una empresa tecnológica recibe actualmente un mayor número de curriculums de hombres que de mujeres, el sistema podría considerar erróneamente que los hombres son mejores porque acaban siendo contratados un mayor número de veces tras el proceso de selección, dejando sin igualdad de oportunidades a las mujeres y provocando situaciones injustas (y pérdida de adquisición de talento en la empresa en cuestión). En este caso, podrían incorporarse datos sintéticos aleatorios en el proceso de entrenamiento para simular un mayor volumen de curriculums de mujeres sin afectar a los resultados pero eliminando este sesgo.
Es solo un ejemplo y puede parecer un poco obvio, pero a menudo pueden escaparse errores de este tipo, o no cuidarse en absoluto, y tener efectos perjudiciales para las personas a corto y largo plazo, o incluso problemas legales para la empresa responsable del modelo.
Como saber si un modelo de IA es válido
En el siguiente artículo puedes leer sobre cómo saber si has acertado a la hora de escoger y depurar tus datos y los algoritmos de tu modelo de aprendizaje, es decir, cómo dar por válido el modelo de inteligencia artificial.
Nos vemos!