El analisis exploratorio de los datos es fundamental cuando trabajamos en Machine Learning, Business Intelligence, Inteligencia Artificial, etc.
Cuanto mejor comprendamos el material de trabajo (los datos) y las herramientas, lógicamente evitaremos un mayor numero de errores, seremos más eficaces, y los resultados serán más precisos.
Índice de la serie de artículos
Iré actualizando esta sección a medida que vaya escribiendo más capítulos sobre el tema
- Introducción y clasificación
- Flujo de trabajo
- Validar el modelo
- Análisis exploratorio
- Algoritmos de Machine Learning:
- Supervisado:
Data Wrangling
La primera etapa del trabajo consistirá en recolectar los datos desde todas las fuentes de datos en las que se encuentren disponibles, limpiarlos, y prepararlos para su análisis. Esta estapa se conoce como Data Wrangling.
A continuación, para entender los datos tendremos que hacer una serie de análisis y visualizaciones, que a menudo requerirán de cierta manipulación. La manipulación de datos tambien será conveniente e imprescindible como paso previo al uso de los datos en los algoritmos de aprendizaje o de cálculo de cualquier tipo que implementemos a continuación, ya que a menudo exigirán que los datos se les entreguen en cierta forma y cumpliendo algunas restricciones.
Las técnicas requeridas para el Data Wrangling como para el Data Analysis dependerán del problema a resolver, del tipo y tamaño de los datos, de su naturaleza, de las tecnologías que estemos empleando, etc. Por esta razón no es mi intención escribir profundizar en este artículo sobre como realizar esta tarea, sino dar unas pinceladas de algunas de las labores más frecuentes que se realizan en esta fase, para hacernos una idea de lo que encontraremos y saber por donde empezar. Esto debería servir como una guia general que ayude a orientarnos en un océano de datos.
Data Frame
Los datos que manejaremos podrán estar almacenados en todo tipo de sistemas de soporte, bases de datos, documentos excel, etc. Es habitual que todas estas herramientas puedan exportar los datos a un formato plano, como por ejemplo CSV, donde cada observación es una fila, y cada columna estaria separada por un elemento separador, como una “coma”.

En la mayor parte de herramientas de analisis de datos (yo suelo utilizar Jupyter Notebooks de Python), permitirán cargar los datos desde diversos formatos, generando un tipo de dato propio que habitualmente se conoce como DataFrame.
El DataFrame es una tabla (con esteroides), donde cada fila representa un registro u observación, y cada columna una característica (feature) de nuestra información.
Operaciones con Data Frames
A medida que vayamos a aplicar visualizaciones y realizar otros análisis, tendremos que hacer manipulaciones y consultas a estos DataFrames. Además, deberán contar con toda la información relevante, y estar limpios de errores, etc.
Esto requerirá combinar Dataframes entre si, extraer subconjuntos de datos, filtrar datos, añadir nuevas columnas, decidir qué hacer con los datos que falten, agrupar, etc.
En este enlace puedes hacerte una idea de las principales operaciones de manipulacion de Dataframes: Cheat Sheet de Data Wrangling con Python.
La idea es transformar los datos para dejar el dataset limpio, es decir:
- se han adaptado adecuadamente los formatos de todas las columnas
- los datos deben ser significativos y de calidad,
- se tienen en cuenta las consideraciones éticas,
- se han eliminado los duplicados, nulos, etc, o se han sustituido por valores adecuados
- las clases deberían estar balanceadas,
- si es necesario, se han reemplazado las características categóricas por columnas dummy
- si es necesario, se han eliminado columnas irrelevantes
- etc.
Análisis básico
Una vez nuestro dataframe está preparado y contiene toda la información necesaria para resultar representativo, comienzan las labores de análisis.
Lo primero que tendremos que conocer es el número de observaciones, el de dimensiones o características, su nombre y significado de cada una de ellas. Tambien será conveniente saber de que tipo es cada columna de datos, y probablemente realizar transformaciones a los tipos adecuados (por ejemplo, un cambo de texto Si/No a booleano, textos que contengan fechas a un formato de fecha nativo en nuestra tecnología, etc.)
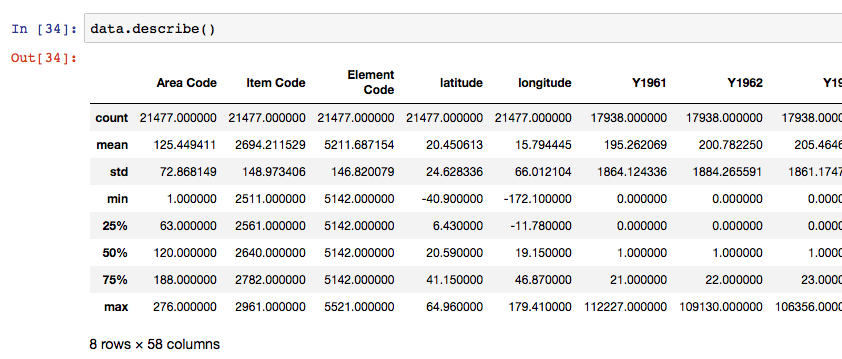
Cada tecnología dispone de sus propias librerias para ello. En python, por ejemplo, podemos usar data.describe() para obtener un resumen de los principales estadisticos de un conjunto de datos.
data.describe() permite obtener un vistazo rapido de la distribución de los datos de cada columna del dataframe
>>> s = pd.Series([1, 2, 3])
>>> s.describe()
count 3.0
mean 2.0
std 1.0
min 1.0
25% 1.5
50% 2.0
75% 2.5
max 3.0
dtype: float64
Visualizaciones
Una forma rápida y fácil de entender los datos para obtener las primeras intuiciones es a través de visualizaciones y representaciones. Cuando trabajemos con muchas caracteristicas, esta alta dimensionalidad dificultará la representación, pero siempre que estemos viendo unas pocas dimensiones, una imagen valdrá mucho más que un montón de valores estadísticos para hacernos una idea rápida general, y nos permitirá comunicar la información a otras personas incluso sin que tengan un background en estadística.
Las representaciones de este tipo se emplean constantemente en todo el proceso, desde el análisis preliminar de los datos hasta el reporting final a los interesados.
Tipos de representación hay innumerables, así como librerias para facilitar su creación. Algunas son muy específicas y pueden venir genial para casos concretos, y otras son de uso muy generalizado y todoterreno, y seguramente sea por las que debamos empezar.
Algunos ejemplos de estas últimas:
Scatterplot o diagrama de dispersión
Se emplea sobre todo para entender la correlación entre varias dimensiones, es decir, cuando queremos entender como varian las dimensiones en función de otras.

Histograma
Esta conocidísima gráfica en forma de barras permite representar de manera proporcional la frecuencia de los valores que toma una variable. De un solo vistazo permiten comprender una idea general de la distribución de una muestra, para comprender tendencias, desbalanceos, valores posibles, homogeneidad, etc.

Boxplot o diagrama de caja
Es una forma de representación estandarizada para visualizar datos numéricos utilizando sus cuartiles. En el diagrama se observa la mediana (valor que toma una variable en el centro del conjunto de datos si se ordenan) dentro de una caja. Los bordes superior e inferior de la caja vienen determinados por los percentiles 25 (cuartil 1, el 25% de los datos son menores o iguales a ese valor) y 75 (cuartil 3, el 75% de los datos son menores o iguales a ese valor). De los extremos de la caja salen los bigotes, que representan el valor máximo y mínimo que toman los valores no atipicos de la variable. La longitud de estos permite saber como de concentrados están los valores. Finalmente, los valores atipicos se representan como puntos aislados.

Otras visualizaciones
Como digo hay muchísimas visualizaciones, así como librerías para representar datos 2D, 3D, animaciones, etc.
Una de las librerías más utilizadas es PyPlot, puedes echar un vistazo a su documentación para ver toda las cosas increibles que puedes llegar a hacer para representar tus datos.
Siguientes pasos
Los objetivos principales del análisis exploratorio son:
- Por un lado, evitar las suposiciones prejuiciosas, evitando errores en los trabajos siguientes gracias a decisiones mejor informadas en base a los datos reales. En definitiva, saber que estas haciendo las preguntas adecuadas.
- Comprender los patrones de datos, valores atípicos, anomalías, desviaciones y descubrir relaciones existentes entre los datos que puedan servir para los modelos de aprendizaje.
- Garantizar que el trabajo que se realizará es válido para los objetivos que se pretenden,
- Del mismo modo, al final del proceso, poder generar interpretaciones de los resultados y conclusiones.
El análisis exploratorio también nos permite entender qué transformaciones de los conjuntos de datos son convenientes para poder aplicar análisis más complejos y, por supuesto, alimentar los algoritmos que permitirán implementar los Modelos de Aprendizaje de nuestra Inteligencia Artificial.
Si te apetece echar un ojo a qué pinta tiene una implementación de un algoritmo de Machine Learning en Python, puedes ver el siguiente post donde encontrarás una implementación básica de algunos ejemplos con árboles de decisión, regresión y random forest.