Actualmente ha empezado a hablarse mucho de machine learning en televisión, en la radio, y en general en programas y fuentes no especializados, que por lo tanto hacen una definición del aprendizaje automático simplificada o “traducida”; al lenguaje específico que entienda su audiencia… esto genera el efecto de que mucha gente crea que el aprendizaje automático es lo mismo que enseñar a una máquina a pensar como una persona, que un ordenador se comporte como un niño pequeño, o incluso cosas más locas.
Cuando entendemos algo del tema o empezamos a trabajarlo en serio, enseguida nos damos cuenta de que realmente el aprendizaje automático es mucho más “simple”;. De hecho, su forma más básica consiste en la aplicación de los algoritmos que hemos visto en los posts anteriores, y desde ahí se avanza y profundiza hasta desarrollar algoritmos mucho más complejos (basados en conceptos matemáticos similares) y más específicos para la resolución de un problema concreto.
En este post vamos a conocer algunos de estos algoritmos, empeando el lenguaje Python.
Como en posts anteriores, veremos que el machine learning consiste basicamente en el diseño y algoritmos capaces de generar modelos que “aprenden”; de los datos observados, y por lo tanto nos permiten hacer predicciones de como se comportaria en los casos que no forman parte de nuestro conjunto de observación.
Como el post me ha quedado un poco largo, aquí tenéis el índice para navegar rápidamente:
- Aprendizaje supervisado y no supervisado
- Métodos Bayesianos
- Clusterización K-Means
- Arboles de decisión
- Conjuntos de clasificadores heterogéneos
- (SVM / SVC) Máquinas de vectores de soporte
- Referencias y créditos
Aprendizaje supervisado y no supervisado
Podemos hacer distintos tipos de clasificaciones de algoritmos de aprendizaje automático, pero la más tipica es distinguirlos por aprendizaje supervisado y no supervisado.
- Algoritmos de aprendizaje no supervisado: entrenaremos el modelo con datos que no tienen “respuestas”; a nuestras preguntas, pero podremos extraerlas del conjunto observado. Por ejemplo, podemos entrenar un modelo con fotografias de perros y de arboles, y el algoritmo, al darle una nueva foto, nos dira si pertenece a uno u otro conjunto, pero no sabrá de qué se trata o qué contiene la foto… esa semántica debemos aportarla nosotros. Este tipo de algoritmo puede emplearse, por ejemplo, para descubrir clasificaciones que no conocíamos que existian en nuestros datos, ya que en principio no sabemos qué estamos buscando, sino que el algoritmo descubrirá por si mismo las variables subyacentes.
- Algoritmos de aprendizaje supervisado: en este caso nuestro algoritmo será entrenado con datos que vienen con la respuesta correcta a nuestras preguntas… de este modo, podemos preguntarle cual sería la respuesta para un nuevo dato que no habíamos observado. Por ejemplo, podemos entrenar un algoritmo con los precios de las viviendas usando datos historicos, donde cada observación tendrá las características de las viviendas y también el precio (que es la respuesta). De este modo, para una nueva vivienda, a partir de sus características obtendríamos el precio apropiado que se ajusta a nuestro modelo.
Los algoritmos supervisados pueden, además, ser evaluados para ver como de preciso resulta nuestro modelo a la hora de predecir nuevos valores. Para ello, una técnica generalmente aplicada consiste en dividir el conjunto de datos en dos subconjuntos (training y test):
- El conjunto Training será alrededor de un 80% de nuestras observaciones, y permitirá entrenar y generar un modelo.
- El conjunto Test será el 20% restante, y nos permitirá evaluar la precisión del modelo generado, ya que podemos comparar la salida que ofrece nuestro algoritmo para cada una de las observaciones con el valor observado correcto, y determinar cuanto estamos fallando en función de la cantidad de error que detectemos.
Para que funcione, entre otras cosas, es necesario que ambos conjuntos sean representativos, que no estén sesgados, etc, algo que generalmente es tan sencillo como escoger las muestras que forman cada conjunto aleatoriamente (cuando las observaciones no tienen sesgos fuertes o distribuciones anómalas, claro).
Aún así, esta iteración entre entrenamiento y test podría arrojar malos resultados, ya que puede que los conjuntos sean demasiado pequeños, o que sean muy parecidos entre ellos, etc. Para resolver este tipo de problemática puede emplearse K-fold cross validation que consiste básicamente en dividir nuestros datos en K subconjuntos aleatorios, e ir rotando sobre ellos calculando el error (cada vez 1 subconjunto será el de test, y el resto formará el de training) , finalmente se calcula la media de error R^2.
Veamos un ejemplo de todo esto:
# Preparamos un conjunto de datos de numero de productos vendidos
# en funcion de su precio
%matplotlib inline
import numpy as np
from pylab import *
np.random.seed(1)
itemPrice = np.random.normal(3.0, 1.0, 100)
itemBuyTimes = np.random.normal(50.0, 30.0, 100) / itemPrice
# Cogemos dos conjuntos aleatorios, el 80% sera e entrenamiento y el 20% de test
# No hace falta hacer "shuffle" porque ya estan aleatoriamente generados
trainX = itemPrice[:80] #del primero al 80
testX = itemPrice[80:] #a partir del 80
trainY = itemBuyTimes[:80]
testY = itemBuyTimes[80:]
# calculamos la función polinómica (de octavo grado)
# que se ajusta a nuestras observaciones
x = np.array(trainX)
y = np.array(trainY)
p4 = np.poly1d(np.polyfit(x, y, 8))
# Representamos la función contra nuestros conjuntos de datos
## Primero el conjunto de entrenamiento
import matplotlib.pyplot as plt
xp = np.linspace(0, 7, 100)
axes = plt.axes()
axes.set_xlim([0,7])
axes.set_ylim([0, 200])
plt.scatter(x, y)
plt.plot(xp, p4(xp), c='r')
plt.show()
## Y ahora el conjunto de test
testx = np.array(testX)
testy = np.array(testY)
axes = plt.axes()
axes.set_xlim([0,7])
axes.set_ylim([0, 200])
plt.scatter(testx, testy)
plt.plot(xp, p4(xp), c='r')
plt.show()
Conjunto Train (entrenamiento): podemos observar como una función polinómica demasiado compleja ha generado un problema de overfitting, ya que ha incluido un ajuste en los outliers.
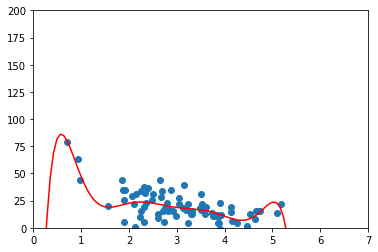
Conjunto de entrenamiento: es demasiado pequeño para un caso real, pero sirve para ver como la función no se ajusta del todo bien debido al overfitting, especialmente en los extremos.
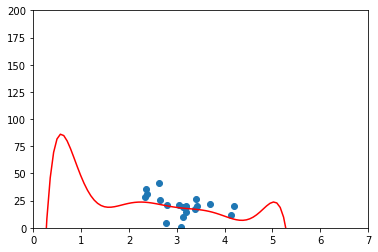
# Calculamos el error R^2 del conjunto de test
from sklearn.metrics import r2_score
r2 = r2_score(testy, p4(testx))
print(r2)
## OUT: 0.10904 - el error es elevadisimo
# Calculamos el error R^2 del conjunto de entrenamiento
from sklearn.metrics import r2_score
r2 = r2_score(np.array(trainY), p4(np.array(trainX)))
print(r2)
## OUT: 0.48944 - es mas alto
Observamos que el score calculado en el conjunto de test es muy bajo, lo que significa un error muy alto, probablemente debido al overfitting de usar una función de 8 grado. Además, en el score del conjunto de entrenamiento, debería ser cercano a 1, ya que es el conjunto con el que precisamente hemos generado el modelo también es absurdamente bajo.
Métodos Bayesianos
Ya hemos explicado en este curso el Teorema de Bayes. Pues bien, esto también puede ser aplicado al aprendizaje automático, y con buenos resultados.
Un ejemplo clásico cuando se habla de aprendizaje automático, es el de crear un sistema capaz de detectar que email es spam y cual no lo se, a partir del contenido o características del email, en este caso nos basaremos en si contiene la palabra Gratis o no para detectar la probabilidad de que sea spam.
Si empleamos la formula que explicaba en ese post anterior, quedaría algo así:
P(Spam|Gratis) = P(Spam)*P(Gratis|Spam) / P(Gratis)
Donde:
- P(Spam) es la probabilidad de que sea spam.
- P(Gratis|Spam) es la probabilidad de que contenga la palabra gratis siendo spam.
- El numerador completo por lo tanto, es la probabilidad de que un mensaje sea spam conteniendo la palabra Gratis.
- El denominador es la probabilidad de que un email contenga la palabra gratis.
- P(Spam|Gratis) es por lo tanto el porcentaje de emails con la palabra Gratis que son spam.
Como podemos imaginar, con este índice no tendremos suficiente, ya que no podemos deciri completamente si un email es spam o no basándonos en la aparición de una sola palabra. Por esta razón, lo que haremos será analizar la probabilidad de que sea spam, como hemos hecho con la palabra Gratis, pero con cada una de las palabras “significativas”; que contenga el email (significativa es que eliminaremos articulos, preposiciones, etc.). Multiplicando la probabilidad de que sea spam para cada una de ellas, obtendremos un índice muy completo que nos permite ver si se trata de spam o no.
Este mecanismos e llama Naive Bayes o Bayes ingenuo ya que asume que las palabras son independientes entre si, algo que por supuesto no deberíamos asumir, ya que probablemente no lo sean… pero no lo tiene en cuenta. Veamoslo en marcha.
# Primero deberíamos cargar un DataFrame con dos propiedades,
# un array de mensajes de cada email (su contenido)
# y un array de etiquetas, spam o nospam en funcion de si lo son o no
# como esta parte no es relevante, la resumo así
data = DataFrame({'message': ["xxx", "yyy", ...], 'class': ["spam", "nospam", "..."]})
# Despues, tokenizamos los mensajes, lo que nos permite saber en cada mensaje
# cuantas veces aparece cada palabra
vectorizer = CountVectorizer()
counts = vectorizer.fit_transform(data['message'].values)
# Ahora utilizamos esos contadores, y la lista de etiquetas de email spam o nospam
# para entrenar el modelo Naive Bayes
classifier = MultinomialNB()
targets = data['class'].values
classifier.fit(counts, targets)
# Finalmente, probamos que funciona con dos emails de ejemplo, uno que parece spam
# y otro que no
examples = ['Get Free Viagra!!!', "Hello Findemor, do you want to play some videogames this weekend?"]
## aplicamos las mismas transformaciones que a los datos de entrenamiento
example_counts = vectorizer.transform(examples)
predictions = classifier.predict(example_counts)
predictions
# OUT: array(['spam', 'nospam'])
Como vemos en el ejemplo, es fácil detectar con bastante precisión si se trata de un mensaje de spam o no, en la mayoría de los casos.
Clusterización K-Means
El ejemplo anterior era un caso de algoritmo supervisado… ahora vamos a ver uno no supervisado.
Los algoritmos de clusterización como K-Means permiten identificar agrupaciones en principio desconocidas de nuestros datos. Por ejemplo, podríamos agrupar un conjunto de peliculas por su genero, valoración, nacionalidad, etc.
El algoritmo K-Means es uno de los más basicos y sencillos, consiste básicamente en escoger un número K de centroides y asignar cada uno de nuestros datos al centroide más cercano. El area en el que los puntos serían asignados a un centroide es denominado cluster.
Para aplicarlo correctamente, entre otras cosas, es necesario que la primera asignación de los centroides sea aleatoria, entonces asignamos cada punto de nuestros datos al centroide más cercano. Recalculamos la posición de los centroides basandonos en la posicion media de cada uno de los puntos asignados a ese centroide, y volvemos a iterar, asignando los puntos en función de la nueva posición del centroide. Si todo ha ido bien (y nuestro conjunto de datos es compatible), los centroides irán desplazandose poco a poco hacia aquellos lugares donde las distancias con los puntos asignados a él sean minimas. Veámoslo gráficamente.
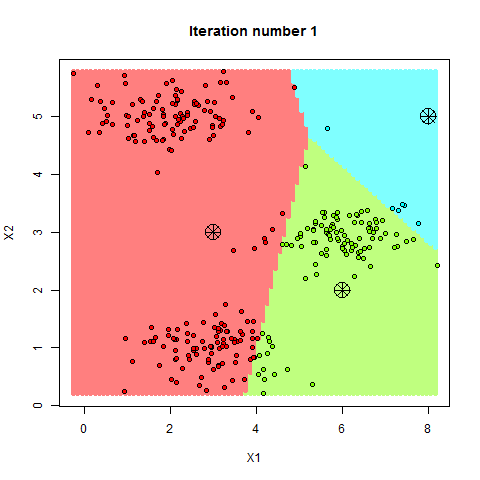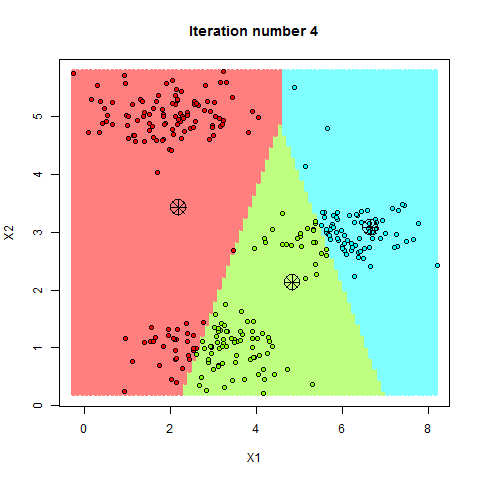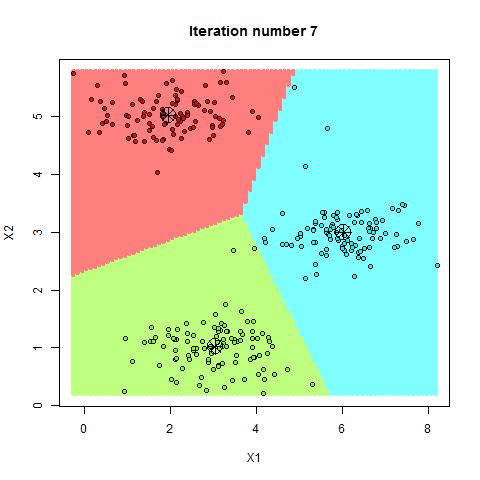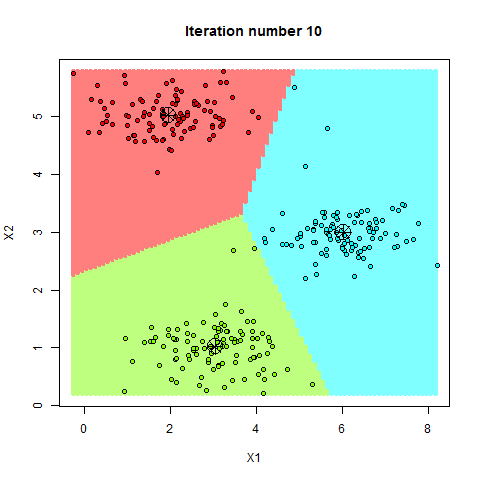 (Ejemplo K-Means, de http://rpubs.com)
(Ejemplo K-Means, de http://rpubs.com)
Por supuesto éste método no es infalible y tiene numerosos aspectos por los que podría generar errores.
- Por ejemplo, no es adecuado para trabajar con datos geográficos, para lo que hay soluciones más apropiadas (OPTICS DBSCAN).
- Elegir el número de clusters tampoco es sencillo, y generalmente es necesario ir probando cada vez con un valor superior de K hasta que veamos que el error no disminuye notablemente.
- Enfrentarse a minimos locales tambien es un problema, ya que si en la posición aleatoria inicial de los centroides coincide que hemos dado con mínimos locales, no se moverán. Para ello podemos por ejemplo inicializar aleatoriamente varias veces y ver que resultados tienen mejores precisiones globales.
- Dar significados a los clusters es un problema sin solución en este algoritmo, ya que sabemos agrupar la información pero desconocemos en principio el significado de las variables latentes que se tuvieron en cuenta para esa asignación… dado que es un algoritmo no supervisado y no tenemos etiquetas.
Veamos como hacerlo en Python.
%matplotlib inline
from sklearn.cluster import KMeans
import matplotlib.pyplot as plt
from sklearn.preprocessing import scale
from numpy import random, float
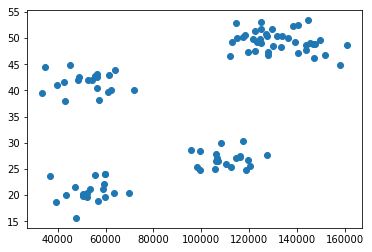
# Primero tendriamos que crear un conjunto de coordenadas aleatorias
# Si tienen algun tipo de "clusterización" pues mejor, por supuesto
data = createSomeRandomValues();
## Lo dibujamos para ver nuestros datos
plt.scatter(data[:,0], data[:, 1])
plt.show()
# Creamos el modelo de KMeans, un valor 5 para K, por ejemplo...
# no hay un valor bueno salvo que conozcamos lo que estamos buscando
# o hagamos pruebas
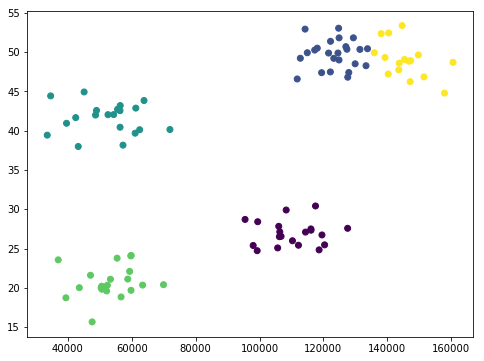
model = KMeans(n_clusters=5)
# Normalizamos los datos, ya que podemos ver en el dibujo anterior
# que las escalas de X e Y son muy distintas
model = model.fit(scale(data))
# Visualizamos el resultado de KMeans dando un color a cada cluster
plt.figure(figsize=(8, 6))
plt.scatter(data[:,0], data[:,1], c=model.labels_.astype(float))
plt.show()
Arboles de decisión
A continuación vamos a ver otro mecanismo para clasificar elementos que funciona de forma muy potente: los árboles de decisión.
Los árboles de decisión son diagramas de flujo que deciden que camino seguir en función del valor de alguna de las variables de los datos. Finalmente, en las hojas del arbol tendremos la respuesta a la clasificación que deseábamos obtener. Como podremos suponer, se trata de un sistema de aprendizaje automático supervisado.
El algoritmo en realidad funciona de forma muy simple, itera sobre los datos escogiendo en cada iteración la variable que minimiza la entropía en los conjuntos de datos que resultan de esa decisión. Así hasta que terminamos con conjuntos de datos etiquetados en cada una de las hojas.
¿Y qué es esta entropía? pues es el grado de desorden de los datos, es decir, un conjunto de datos donde tenemos por ejemplo 3 tipos de etiquetas y hay 100 datos con cada una de las etiquetas, tendrá una entropía alta. Por el contrario, si tenemos solo 1 etiqueta para cualquier numero de datos, la entropía será minima, ya que todos los datos pertenecen al mismo conjunto y por lo tanto no hay desorden. Con este algoritmo buscaremos que la entropía en cada hoja sea mínima, aunque eso implique que el arbol no sea óptimo en cuanto a número de decisiones.
import numpy as np
import pandas as pd
from sklearn import tree
# Cargariamos un csv con datos de curriculums, por ejemplo
input_file = "C:\curriculums.csv"
df = pd.read_csv(input_file, header = 0)
# mostramos el contenido
df.head()
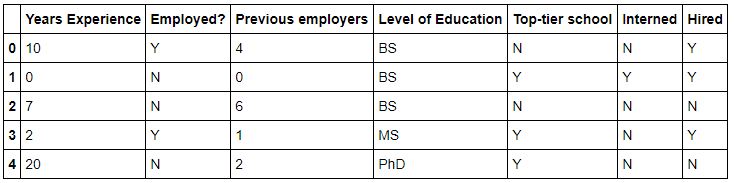
# Creamos un objeto para mapear las variables categoricas en numericas,
# que son las que acepta el algoritmo
d = {'Y': 1, 'N': 0}
# aplicamos la transformación
df['Hired'] = df['Hired'].map(d)
df['Employed?'] = df['Employed?'].map(d)
df['Top-tier school'] = df['Top-tier school'].map(d)
df['Interned'] = df['Interned'].map(d)
# hacemos lo mismo con el nivel de educacion
d = {'BS': 0, 'MS': 1, 'PhD': 2}
df['Level of Education'] = df['Level of Education'].map(d)
# Observamos el resultado de la transformacion de variables categoricas
# en numericas
df.head()
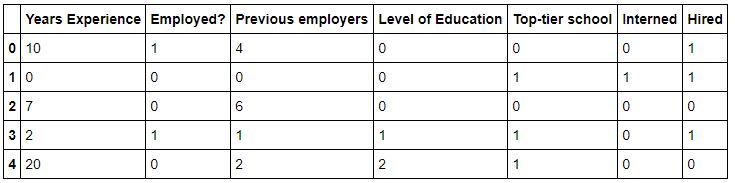
# Seleccionamos las primeras 6 columnas, que contienen las caracteristicas
# de la observacion (sin la clase Hired, que es la respuesta que queremos calcular)
features = list(df.columns[:6])
X = df[features]
# Seleccionamos de forma aislada la columna que contiene la etiqueta a entrenar
y = df["Hired"]
# Y finalmente generamos el arbol de decision a partir de estos datos
clf = tree.DecisionTreeClassifier()
clf = clf.fit(X,y)
################################################
## Si queremos visualizar el modelo, basta con emplear la libreria graphviz
## quedaría asi
from IPython.display import Image
from sklearn.externals.six import StringIO
import pydotplus
dot_data = StringIO()
tree.export_graphviz(clf, out_file=dot_data,
feature_names=features)
graph = pydotplus.graph_from_dot_data(dot_data.getvalue())
Image(graph.create_png())
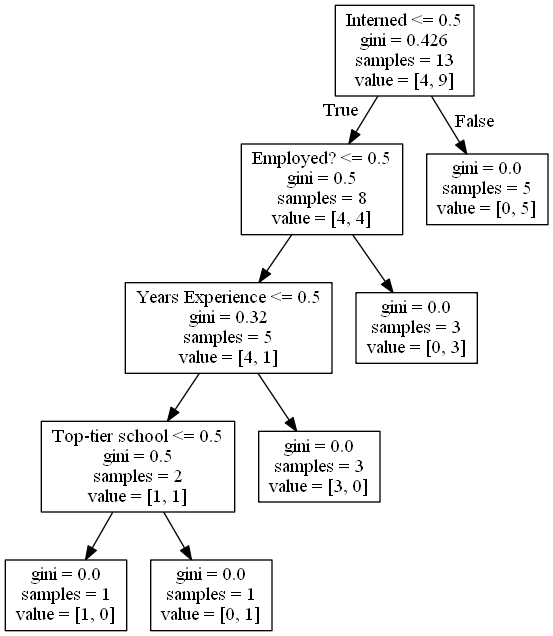
Resultado del árbol de decisión.
Podemos ver como el modelo ha generado una serie de decisiones que desembocan de un modo u otro en la decisión de si ese curriculum corresponde a alguien que debe ser contratado o no. Hay unos pocos parámetros en cada decisión que debemos conocer para comprender e interpretar el resultado:
Random Forests
El problema de los arboles de decisión es que son muy propensos al overfitting, es decir, a ajustarse demasiado a los datos del conjunto observado y ofrecer buenos resultado en él, pero no ser capaz de predecir correctamente nuevos valores. Para evitar este efecto una posible solución consiste en aplicar una variante denominada Random Forests.
Random Forests consiste básicamente en escoger aleatoriamente subconjuntos de datos del conjunto observado y generar distintos árboles de decision para cada uno de esos conjuntos. Después, para cada observación, todos los árboles votan cual es la clase resultado para dicha observación. Además, los árboles permiten seleccionar cual de las variables son tenidas en cuenta en cada paso para escoger la clase de la observación.
Utilizando los mismos datos del clasificador anterior basado en un árbol de decisión normal, vamos a ver como podríamos crear un modelo de tipo Random Forest en su lugar:
from sklearn.ensemble import RandomForestClassifier
# Basta con aplicar este otro método en lugar del anterior
clf = RandomForestClassifier(n_estimators=10)
clf = clf.fit(X, y)
##################################
# Despues, podemos ver el resultado a un par de curriculums nuevos para los que
# nuestro sistema no ha sido entrenado
# ¿Debemos contratar a un profesional con 10 años de experiencia
# que actualmente tiene trabajo?
print (clf.predict([[10, 1, 4, 0, 0, 0]]))
### OUT: [1] ... Nuestro arbol de decisión diria que sí
# ¿Y que pasa si actualmente está desempleado?
print (clf.predict([[10, 0, 4, 0, 0, 0]]))
### OUT: [0] ... Nuestro arbol de decisión opina que no
Ocurre una cosa curiosa… si ejecutamos varias veces la prediccion sobre el mismo curriculum, en algunos casos a veces podría dar una respuesta positiva y otras negativa… esto se debe a la naturaleza aleatoria de la generación del modelo Random Forest. Si los arboles cambian sutilmente, las predicciones también podrían cambiar.
Conjuntos de clasificadores heterogéneos
A veces es buena idea no limitarse a un único algoritmo de clasificación, sino combinar varios de ellos para generar un resultado más preciso o mejores predicciones. De hecho, acabamos de ver esta técnica aplicada en el apartado anterior, ya que un clasificador Random Forest es un conjunto de clasificadores, debido a que escoge subconjuntos aleatorios de datos de nuestras observaciones, y los emplea para generar unos cuantos clasificadores distintos (cada uno de los cuales votará después por un resultado para las nuevas observaciones que lleguen).
Existen distintas técnicas para generar conjuntos de clasificadores (ensemble learning), entre ellas:
- Bagging (Bootstrap aggregating): la utilizada por Random Forest… muchos modelos entrenados con subconjuntos aleatorios de los datos.
- Boosting: parecido al anterior, pero cada modelo siguiente que se genera intenta aumentar el peso (boost) los atributos que hicieron que los datos se clasificasen erróneamente en el modelo anterior.
- Bucket: entrena muchos modelos distintos, empleando distintos algoritmos pero los mismos datos de entrenamiento, despues se utiliza aquel que ofrece mejor precisión con el conjunto de test.
- Stacking: se ejecutan varios modelos distintos en los mismos datos de entrenamiento, pero en este caso los resultados se fusionan, con lo que la clasificación final es el resultado combinado de todos los clasificadores empleados (votación, asignación de pesos/credibilidad, etc.).
Existen técnicas avanzadas para obtener mejores resultados a la hora de combinar de forma inteligente estos algoritmos de clasificación, como por ejemplo:
- Clasificador Optimo de Bayes: ofrece los resultados más precisos pero es computacionalmente muy costoso, por lo que resulta dificil de utilizar en la vida real.
- Bayesian Parameter Averaging: intenta ser más eficiente que el anterior a costa de su precisión, pero al parecer resulta sensible al overfitting y suele tener peor rendimiento que técnicas más simples como Bagging.
- Combinación de modelos Bayesianos: un modelo que trabaja sobre las ideas anteriores, pero que en realidad parece no ofrecer resultados mucho mejores que las técnicas de Stacking, más sencillas.
(SVM / SVC) Máquinas de vectores de soporte
Anteriormente hemos hablado de técnicas como K-means, que permiten clasificar y clusterizar datos en función de una serie de características (funciona bien con 2 características o unas pocas)… en ocasiones, sin embargo, el número de características de las cuales depende nuestro sistema de clasificación es muy elevado, y si por lo que sea ninguna de ellas puede ser obviada y eliminada de nuestros cálculo, entonces deberemos recurrir a técnicas que trabajen bien con datos con un gran número de dimesiones, como es el caso de este algoritmo: Support Vector Machines.
Las SVM son algoritmos que funcionan bien, como hemos dicho, con observaciones cuya clasificación depende de un gran número de variables, ya que emplean una serie de hiperplanos (matemáticassss) para realizar la clasificación. Debido a esta razón, son computacionalmente muy caras… y por lo general existen diferentes aproximaciones en las librerias que emplearemos para su implementación, que proporcionan mejor o peor resultado en función del “performance”; que ofrezcan. Además, es importante resaltar que pese a que lo he comparado antes con K-Means, en realidad SVM se trata de un algoritmo supervisado, que requiere de un conjunto de entrenamiento correctamente etiquetado para generar su modelo.
En la imagen siguiente podemos ver el resultado de clasificar el conjunto de datos Iris aplicando algunos de los distintos Kernels de SVC (Support Vector Classification). En el ejemplo pueden distinguirse los resultados menos precisos que ofrecería un SVC Lineal (primera imagen) frente a los polinómicos (última imagen), pero por supuesto estos últimos tienen un mayor coste computacional. A menudo que funcionen unos mejores que otros dependen del conjunto de datos sobre el que lo empleemos.
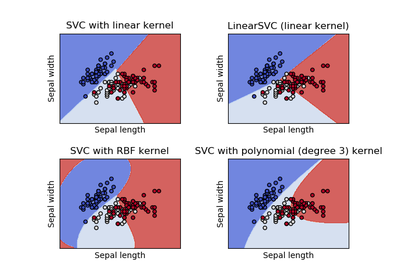
Comparación de SVC Kernels (http://scikit-learn.org)
Hagamos algunas pruebas con Python.
%matplotlib inline
from pylab import *
# Primero creamos algunos datos de prueba, en nuestro caso preparamos dos arrays
# X contiene vectores bidimensionales, que determinan las coordenadas X e Y de
# nuestros datos X = [[1,0],[x, y],...]
# Y contiene un valor de 1 a 5 que corresponde a la etiqueta que asignamos a cada
# observacion de nuestro conjunto de entrenamiento
(X, y) = createRandomData(5)
# Pintamos los datos para ver que tenemos entre manos
plt.figure(figsize=(8, 6))
plt.scatter(X[:,0], X[:,1], c=y.astype(np.float))
plt.show()
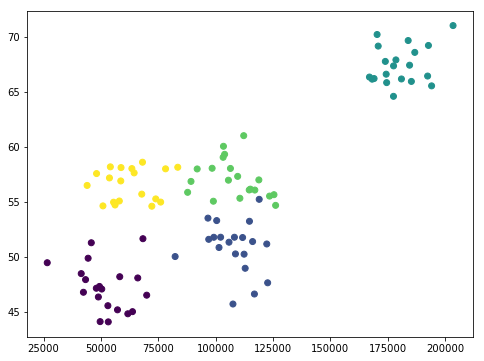
Nuestros datos
from sklearn import svm, datasets
# Creamos un modelo SVC usando el kernel lineal (el menos costoso)
svc = svm.SVC(kernel='linear', C=1.0).fit(X, y)
########################
# Si queremos podemos ver en que cluster clasificaria
# un par de nuevas observaciones...
print(svc.predict([[100000, 40]]))
## OUT: [1] ... lo clasifica en el cluster 1
print(svc.predict([[50000, 70]]))
## OUT: [4] ... lo clasifica en el cluster 4
## Veamos los datos representados
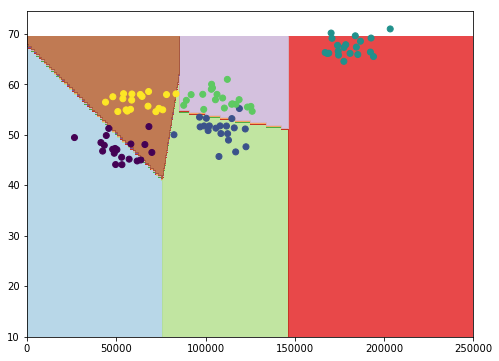
Resultado SVC Linear
¡Se acabó por ahora! Espero que mis apuntes os hayan resultado tan útiles como a mí, y os invito a consultar los siguientes enlaces.
Referencias y créditos
He utilizado ejemplos y conocimientos de los que aprendí en este curso, el cual os animo a realizar:
- Curso Data Science: https://www.udemy.com/data-science-and-machine-learning-with-python-hands-on